Rechtschreibprüfung: LanguageTool-Server in Docker betreiben

Auf der Suche nach einer besseren Rechtschreibprüfung für den Browser bin ich auf die Open-Source-Software LanguageTool gestoßen. LanguageTool korrigiert Fehler für die Sprachen Englisch, Spanisch, Französisch, Deutsch, Portugiesisch, Polnisch, Niederländisch und mehr als 20 weitere Sprachen. Dabei findet LanguageTool auch Fehler, die eine einfache Rechtschreibprüfung nicht erkennen kann. Wer seine Texte nicht an ein Cloud-Service schicken will, kann selbst einen LanguageTool-Server betreiben. Nachdem der Service auch als Docker-Version verfügbar ist, lässt sich dieser einfach auf einem beliebigen Rechner oder Server starten und im eigenen Netzwerk verwenden.
Browser-Plugin
LanguageTool ist als Browser-Plugin für die bekannten Webbrowser, wie Google Chrome, Firefox oder Edge verfügbar. Das Plugin schickt alle im Browser eingegebenen Texte standardmäßig an die URL: https://languagetool.org.

Funktionsweise
LanguageTool untersucht alle Eingabefelder und kann universell für alle Webseiten oder Webanwendungen eingesetzt werden.

Erweiterte Einstellungen – eigener Server-Service
Wer seinen eigenen LanguageTool-Server betreibt, kann dessen Adresse im Browser-Plugin hinterlegen.
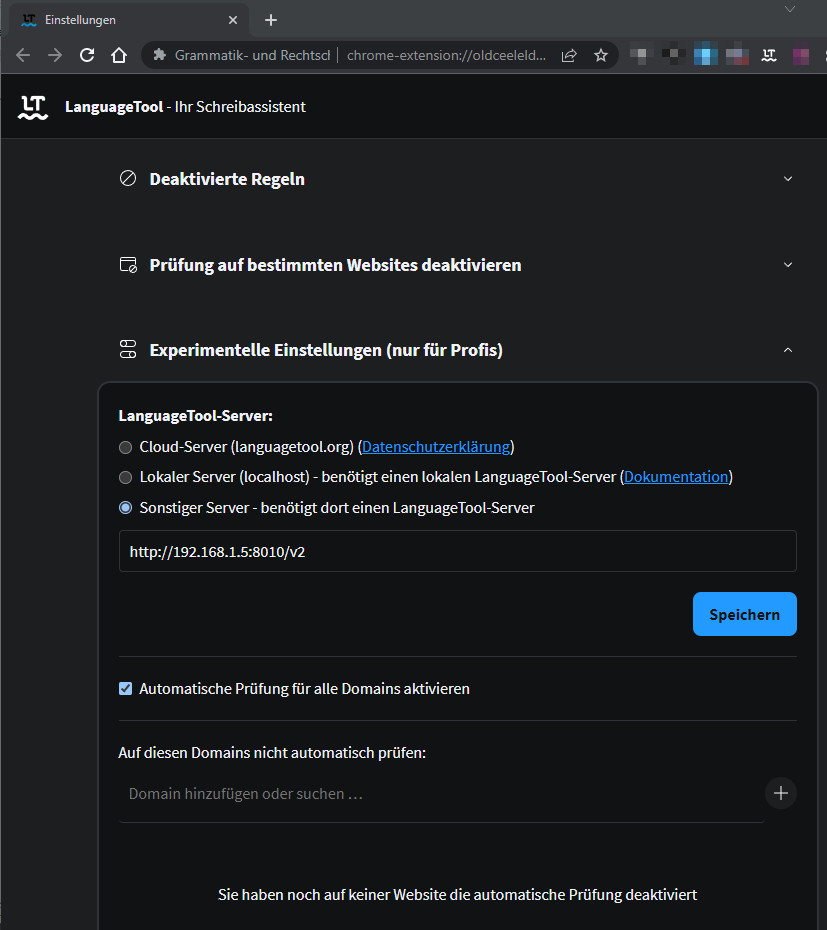
Docker-Container starten
Docker Basics
Docker ermöglicht es, Services oder Applikationen per Befehl in einem sogenannten Container zu starten.Ein Container ist eine vom Betriebssystem (OS) unabhängige isolierte Umgebung:
Beim ersten Start eines Containers, lädt Docker selbstständig alle notwendigen Quellen
aus dem Internet.
Docker kann unter Windows, macOS oder einer Linux-Distribution installiert werden,
siehe auch: Docker
version: "3"
services:
languagetool:
image: erikvl87/languagetool
container_name: languagetool
ports:
- 8010:8010 # Using default port from the image
environment:
- langtool_languageModel=/ngrams # OPTIONAL: Using ngrams data
- Java_Xms=2g # OPTIONAL: Setting a minimal Java heap size of 512 mib
- Java_Xmx=4g # OPTIONAL: Setting a maximum Java heap size of 1 Gib
- timeoutRequestLimit=120
volumes:
- ./ngrams:/ngrams
restart: alwaysDamit LanguageTool auch bei längeren Texten funktioniert, habe ich im Beispiel die "Java heap size": "Java_Xms" auf 2g und "Java_Xmx" auf 4g gesetzt. Der Ordner ./ngrams sollte für eine genauere Rechtschreibprüfung mit NGRAM-Daten befüllt werden.
NGRAM-Data
Um die Genauigkeit des Servers zu erhöhen, können sogenannte NGRAM-Data verwendet werden. NGRAM Daten sind zerlegte Textfragmente, mit dessen Hilfe statische Wahrscheinlichkeiten für die Rechtschreibprüfung einfließen können. Der Download der NGRAM-Data ist unter folgender URL erhältlich: languagetool.org/download/ngram-data/. Die Zip-Files sollten in den ngrams Unterordner entpackt werden:

Auf einem Linux-Rechner können die Daten wie folgt über das Terminal geladen und entpackt werden:
wget https://languagetool.org/download/ngram-data/ngrams-de-20150819.zip
cd ngrams && unzip ../ngrams-de-20150819.zip
cd ..
wget https://languagetool.org/download/ngram-data/ngrams-en-20150817.zip
cd ngrams && unzip ../ngrams-en-20150817.zipFazit
Das LanguageTool hat eine sehr gute Erkennungsleistung und betrachtet dabei nicht nur einzelne Wörter, sondern ganze Sätze. Neben der Rechtschreibprüfung und Beistrichsetzung werden auch Sätze markiert, bei denen eine mögliche Stilverbesserung festgestellt wird, als Beispiel Wortwiederholungen oder zu lange Sätze. Nachdem LanguageTool auf dem eigenen Server betreiben werden kann, steht auch dem Einsatz für sensible Texte nichts im Weg.
 ({{pro_count}})
({{pro_count}})
{{percentage}} % positiv
 ({{con_count}})
({{con_count}})