Home Assistant Daten als Tabelle anzeigen / Reporting
Charts sind super, aber für bestimmte Auswertungen wäre eine einfache Tabellenansicht historischer Daten wünschenswert. Bedauerlicherweise hat Home Assistant in Sachen Reporting, out of the box, sehr wenig zu bieten. Nur bestimmte Cards können auf die History Daten zugreifen, dann aber ohne einer Möglichkeit die Daten aufzubereiten, zu filtern, oder anzupassen. Als Lösung arbeite ich parallel zu dieser Anleitung an eine HACS-Integration: jetzt verfügbar: Tabellen & Auswertungen in Home Assistant.
Über Umwege ist es möglich beliebige SQL-Abfragen der Datenbank in einer Lovelace-Card als Tabelle auszugeben. Warum das so ist, siehe: Home Assistant Besonderheiten: Stärken und Schwächen
Hier das Ziel dieses Beitrags:
Das hier präsentierte Beispiel umfasst Daten von fünf verschiedenen Entitäten, die aus der Datenbank ausgelesen, in einer Entität gespeichert und über eine Markdown-Card in Lovelace ausgegeben werden. In der Markdown-Card können bestimmte Spalten auf Basis der Werte von anderen Spalten berechnet werden: z. B. wird die Spalte: "Delta" aus "Vorlauf" und "Rücklauf" berechnet. Für dieses Beispiel habe ich die Custom-Integration sql_json verwendet. Aber auch ohne der HACS-Integration sql_json können bestimmte Datenbank-Werte in einer Lovelace-Card angezeigt werden:
☑ SQL-Integration: JSON
Mithilfe der vorhandenen SQL-Integration ist es möglich, das Ergebnis für bestimmte SQL-Abfragen in einem eigenen Sensor zu speichern, siehe: Home Assistant SQL - Integration. Gespeichert im JSON-Format, können die Daten relativ einfach über eine Markdown-Card als Tabelle ausgegeben werden. Hier ein konkretes Beispiel für den täglichen PV-Ertrag: SQL-Integration Sensor, siehe:

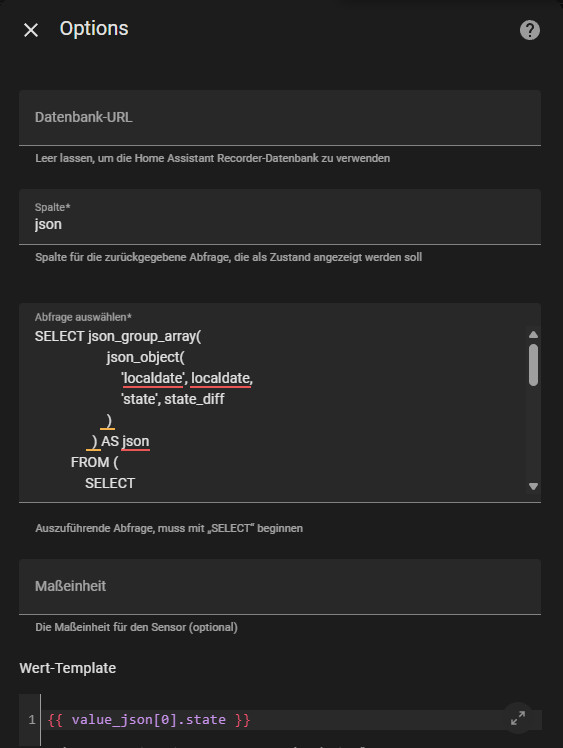
Nachfolgend die verwendete SQL-Query für eine fortlaufende Entität (Energiezähler):
SELECT json_group_array(
json_object(
'localdate', localdate,
'state', state_diff
)
) AS json
FROM (
SELECT
ROUND(MAX(state) - MIN(state), 2) AS state_diff,
DATE(datetime(created_ts, 'unixepoch', 'localtime')) AS localdate
FROM
statistics
WHERE
metadata_id = (
SELECT id
FROM statistics_meta
WHERE statistic_id = 'sensor.pv_panels_energy'
)
AND state NOT IN ("unknown", "", "unavailable")
GROUP BY
localdate
ORDER BY
localdate DESC
LIMIT 100
);Der Sensor: sensor.pv_panels_energy muss natürlich entsprechend angepasst werden. Damit die Abfrage funktioniert, sollte diese vorab getestet werden, siehe: 3 Varianten: SQLite Datenbank Zugriff - Home Assistant.
Die Query speichert die Werte als Attribute, wodurch es, im Gegensatz zum Entity-Wert, möglich ist, mehr als 255 Zeichen zu speichern.
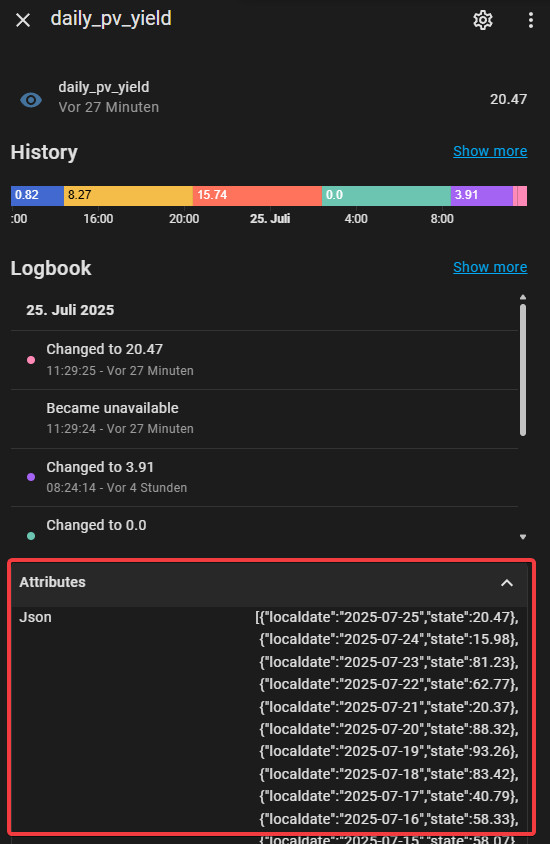
Diese Werte können dann in einer Markdown-Card als Tabelle angezeigt werden:
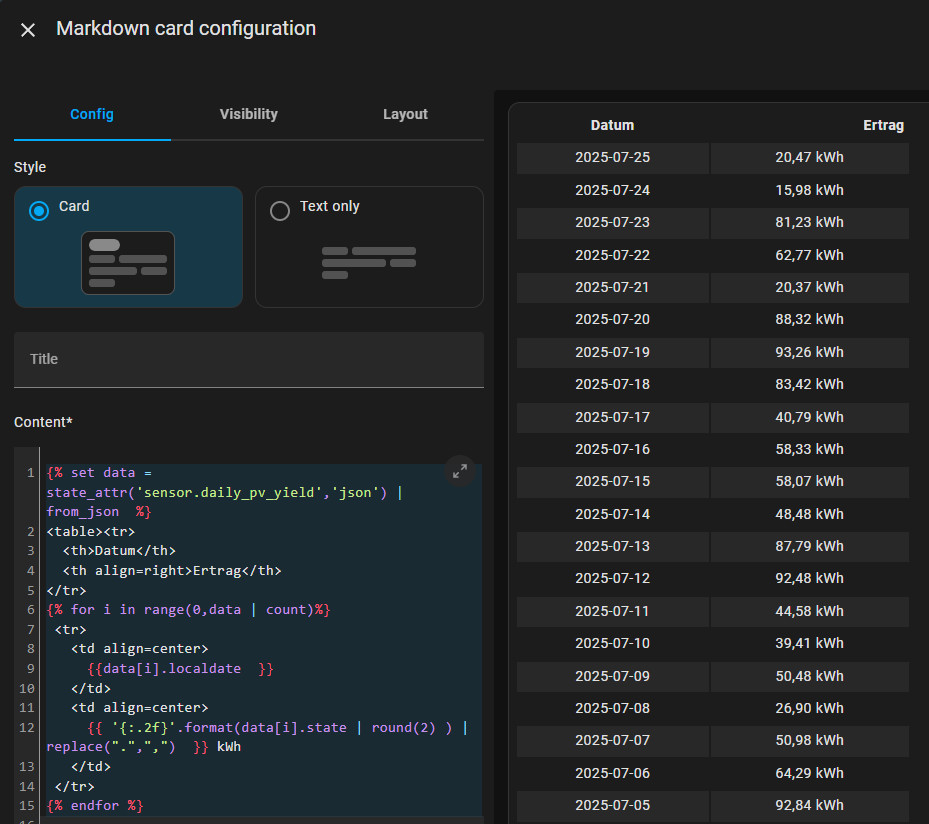
Markdown:
{% set data = state_attr('sensor.daily_pv_yield','json') | from_json %}
<table><tr>
<th>Datum</th>
<th>Ertrag</th>
</tr>
{% for i in range(0,data | count)%}
<tr>
<td align=center>
{{data[i].localdate }}
</td>
<td align=center>
{{ '{:.2f}'.format(data[i].state | round(2) ) | replace(".",",") }} kWh
</td>
</tr>
{% endfor %}
Achtung bei großen Datenmengen: Abfragen laufen alle 30 Sekunden
Per Default werden die SQL-Abfragen alle 30 Sekunden ausgeführt wodurch Home Assistant sehr schnell ausgebremst werden könnte, entsprechend sollten große Abfragen aus dem Standard-Polling ausgenommen werden:
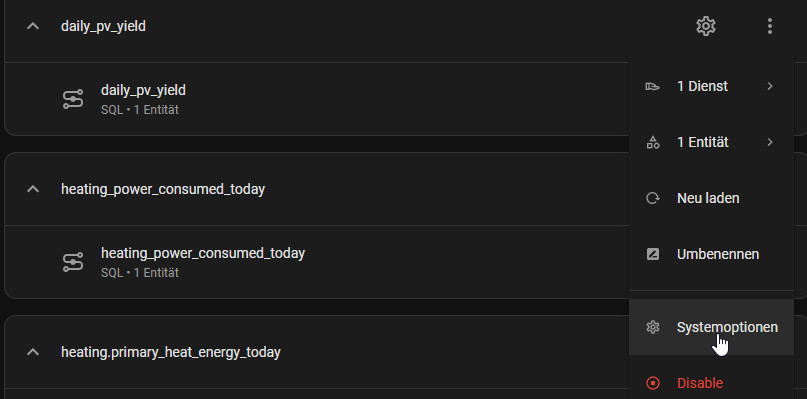

Die Query kann bei Bedarf über ein Skript oder regelmäßig über eine Automatisierung ausgeführt werden:
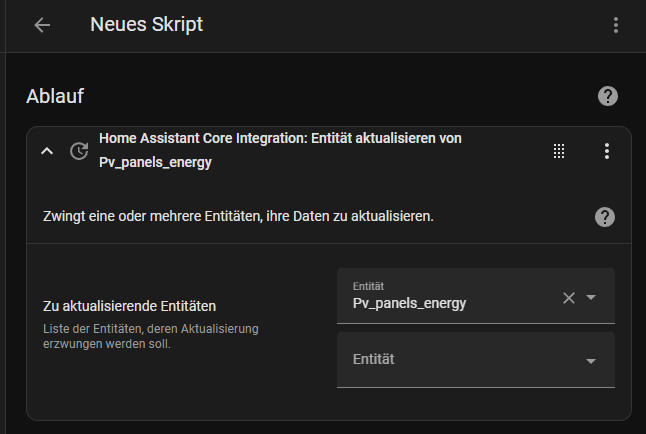
Bestimmte Entitäten in einer Query kombinieren
Mit dieser Variante können die Daten mehrerer Sensoren kombiniert werden, hier die zugehörige Query zu dem anfangs in diesem Artikel präsentierten Beispiel:
SELECT json_group_array(
json_object(
'localdate', flowmeter_sum.localdate,
'flowmeter_sum', flowmeter_sum.state_diff,
'aussen_temperatur_mean', aussen_temperature.state_mean,
'flowmeter', flowmeter.state,
'heating_vorlauf', heating_vorlauf.state_min,
'heating_ruecklauf', heating_ruecklauf.state_min
)
) AS json
FROM (
SELECT
ROUND(MAX(state) - MIN(state), 2) AS state_diff,
DATE(datetime(created_ts, 'unixepoch', 'localtime')) AS localdate
FROM
statistics
WHERE
metadata_id = (
SELECT id
FROM statistics_meta
WHERE statistic_id = 'sensor.flowmeter_sum'
)
AND state NOT IN ("unknown", "", "unavailable")
AND DATE(datetime(created_ts, 'unixepoch', 'localtime')) < DATE('now')
GROUP BY
localdate
ORDER BY localdate DESC
) flowmeter_sum
LEFT JOIN (
SELECT
ROUND(AVG(mean), 2) AS state_mean,
DATE(datetime(created_ts, 'unixepoch', 'localtime')) AS localdate
FROM
statistics
WHERE
metadata_id = (
SELECT id
FROM statistics_meta
WHERE statistic_id = 'sensor.aussen_temperature'
)
AND mean NOT IN ("unknown", "", "unavailable")
GROUP BY
localdate
) aussen_temperature ON flowmeter_sum.localdate = aussen_temperature.localdate
LEFT JOIN (
SELECT
ROUND(max(mean), 2) AS state,
DATE(datetime(created_ts, 'unixepoch', 'localtime')) AS localdate
FROM
statistics
WHERE
metadata_id = (
SELECT id
FROM statistics_meta
WHERE statistic_id = 'sensor.flowmeter'
)
AND max NOT IN ("unknown", "", "unavailable")
GROUP BY
localdate
) flowmeter ON flowmeter.localdate = aussen_temperature.localdate
LEFT JOIN (
SELECT
ROUND(min(min), 2) AS state_min,
DATE(datetime(created_ts, 'unixepoch', 'localtime')) AS localdate
FROM
statistics
WHERE
metadata_id = (
SELECT id
FROM statistics_meta
WHERE statistic_id = 'sensor.heating_ruecklauf'
)
AND max NOT IN ("unknown", "", "unavailable")
GROUP BY
localdate
) heating_ruecklauf ON flowmeter.localdate = heating_ruecklauf.localdate
LEFT JOIN (
SELECT
ROUND(min(min), 2) AS state_min,
DATE(datetime(created_ts, 'unixepoch', 'localtime')) AS localdate
FROM
statistics
WHERE
metadata_id = (
SELECT id
FROM statistics_meta
WHERE statistic_id = 'sensor.heating_vorlauf'
)
AND max NOT IN ("unknown", "", "unavailable")
GROUP BY
localdate
) heating_vorlauf ON heating_ruecklauf.localdate = heating_vorlauf.localdate;Markdown-Card-Inhalt:
{% set data = state_attr('sensor.daily_heating','json') | from_json %}
<table><tr>
<th>Datum</th>
<th align=right>Flowmeter SUM</th>
<th align=right>AVG Aussen</th>
<th align=right>Flowmeter</th>
<th align=right>Delta</th>
<th align=right>Vorlauf</th>
<th align=right>Rücklauf</th>
</tr>
{% for i in range(0,data | count)%}
<tr>
<td align=right>
{{data[i].localdate }}
</td>
<td align=right>
{{ '{:.2f}'.format(data[i].flowmeter_sum | round(2)) }} m³
</td>
<td align=right>
{{ '{:.2f}'.format(data[i].aussen_temperatur_mean | round(2, 'floor')) }} °C
</td>
<td align=right>
{{ '{:.2f}'.format(data[i].flowmeter| round(2, 'floor'))}} m³/h
</td>
<td align=right >
{{ '{:.1f}'.format((data[i].heating_vorlauf - data[i].heating_ruecklauf) | round(1, 'floor')) }} °C
</td>
<td align=right>
{{ '{:.1f}'.format(data[i].heating_vorlauf | round(1, 'floor')) }} °C
</td>
<td align=right>
{{ '{:.1f}'.format(data[i].heating_ruecklauf | round(1, 'floor')) }} °C
</td>
</tr>
{% endfor %}
Markdown-Card Limit
Die Darstellung von Daten mit über 262144 Zeichen überfordert die Markdown-Card und führt zu einem Fehler:

Eine Möglichkeit das Limit der Markdown-Card zu umgehen ist ein Helper für die Anzeige von Seiten: "input_number.heating_pagination"

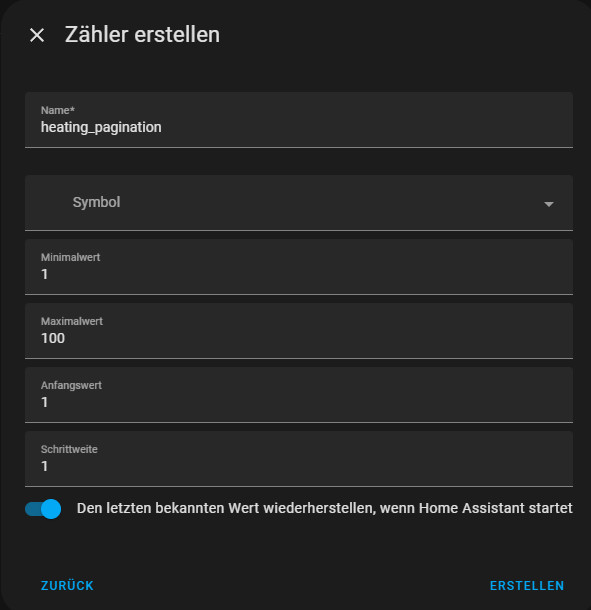
Der Helfer kann dann in der Markdown-Card verwendet werden. Die Variable "numlist" limitiert die Anzahl der Einträge pro Seite:
type: markdown
content: |
{% set data = state_attr('sensor.daily_heating','json') | from_json %}
{% set pagination = states('input_number.heating_pagination') | int(0) %}
{% set numlist = 500 %}
{% set start = (pagination * numlist) - numlist %}
{% set end = start + numlist %}
{% if(end > (data | count)) %}
{% set end = data | count %}
{% endif %}
<table><tr>
<th>Datum</th>
<th align=right>Flowmeter SUM</th>
<th align=right>AVG Aussen</th>
<th align=right>Flowmeter</th>
<th align=right>Runtime</th>
<th align=right>Delta</th>
<th align=right>Heizleistung</th>
<th align=right>Vorlauf</th>
<th align=right>Rücklauf</th>
</tr>{#data | count#}
{% for i in range(start, end)%}
<tr>
<td align=right>
{{data[i].localdate }}
</td>
<td align=right>
{% if (data[i].flowmeter | float(0) > 0.5) %}{{ '{:.2f}'.format(data[i].flowmeter_sum | float(0) | round(2)) }}{% else %}-{% endif %} m³
</td>
<td align=right>
{{data[i].aussen_temperatur_mean | float("n/a")}} °C
</td>
<td align=right>
{{ '{:.2f}'.format(data[i].flowmeter| float(0) | round(2, 'floor'))}} m³/h
</td>
<td align=right>
{% if (data[i].flowmeter | float(0) > 0.5) %}{{ '{:.2f}'.format(data[i].flowmeter_sum | float(0) / data[i].flowmeter | float(0) | round(2, 'floor'))}}{% else %}-{% endif %}h
</td>
<td align=right >
{% if (data[i].flowmeter | float(0) > 0.5) %}{{ '{:.1f}'.format((data[i].heating_vorlauf | float(0) - (data[i].heating_ruecklauf) | float(0)) | round(1, 'floor')) }}{% else %}-{% endif %} °C
</td> <td align=right >
{% if (data[i].flowmeter | float(0) > 0.5) %}{{ '{:.1f}'.format(((data[i].heating_vorlauf | float(0) - (data[i].heating_ruecklauf) | float(0))) * 1.163 * data[i].flowmeter_sum | float(0) | round(2, 'floor')) }}{% else %}-{% endif %} kWh
</td>
<td align=right>
{{ '{:.1f}'.format(data[i].heating_vorlauf | float(0) | round(2, 'floor')) }} °C
</td>
<td align=right>
{{ '{:.1f}'.format(data[i].heating_ruecklauf | float(0) | round(2, 'floor')) }} °C
</td>
</tr>
{% endfor %}
grid_options:
columns: full
text_only: true
card_mod:
style:
ha-markdown:
$:
ha-markdown-element: |
table {
width: 100%;
padding: 10px;
margin: -20px!important;
}
th, td {
padding: 4px;
overflow: hidden;
text-overflow: ellipsis;
white-space: nowrap;
}
tr:nth-child(even) {
background-color: var(--secondary-background-color);
}
Das Beispiel zeigt die "Code-Editor-Ansicht (YAML)" und nutzt die HACS-Integration "Card_Mod" und damit umgesetzt CSS-Styles:
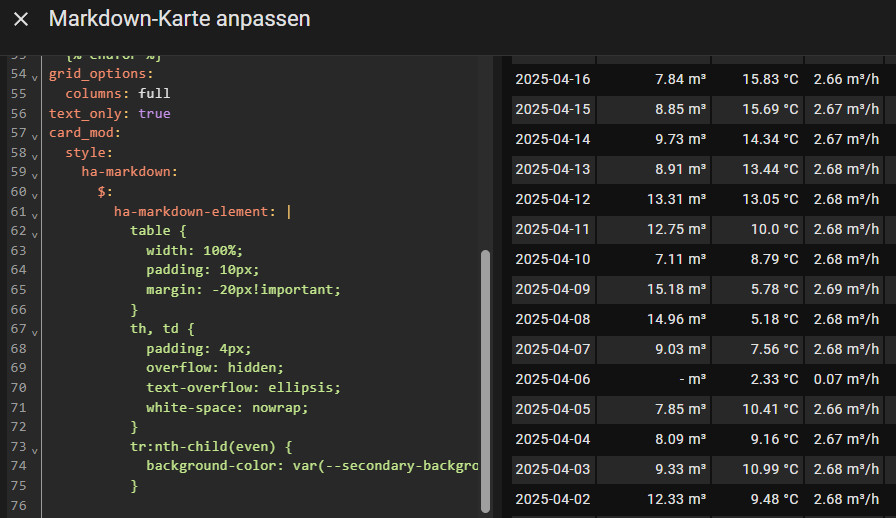
Durch Hinzufügen des Helfers für die aktuelle Seite lässt sich in 500-er Schritten zwischen den Seiten wechseln.
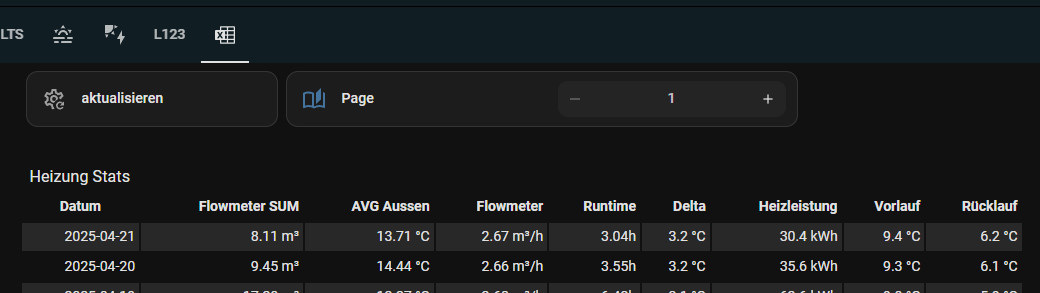
Anstelle einer fixen Anzahl, könnte auch das Jahr für die Pagination verwendet werden:
...
{% for i in range(0, (data | count)) if (strptime(data[i].localdate, '%Y-%m-%d').year == pagination)%}
...Card-Mod Style
Beim Einsatz der HACS-Integration Card-Mod kann das Layout der Tabelle angepasst werden, wie in den Beispielen gezeigt, unterschiedliche Hintergründe für gerade und ungerade Zeilen.
...
card_mod:
style:
ha-markdown:
$:
ha-markdown-element: |
table {
width: 100%;
padding: 10px;
margin: -20px!important;
}
th, td {
padding: 4px;
overflow: hidden;
text-overflow: ellipsis;
white-space: nowrap;
}
tr:nth-child(even) {
background-color: var(--secondary-background-color);
}alternative Anzeige: HACS-Integration: Flex Table
Etwas komfortabler beim Einrichten, dafür aber weniger flexibel ist die Integration Flex Table:

Für einfache Tabellen ok, aber spätestens beim Verknüpfen oder Berechnen bestimmter Spalten stößt die Flex Table-Card an ihre Grenzen, daher würde ich die Markdown-Card der Flex-table Card vorziehen.
ⓘ Daten direkt aufrufen, Plotly-Graph-Table
Die Tabellenansicht von Plotly-Graph darf an dieser Stelle nicht unerwähnt bleiben. Eigentlich für die Anzeige von Charts kann Plotly-Graph historische Daten auch als Tabelle anzeigen: Direkt und ohne vorab eine Query zu verwenden.
type: custom:plotly-graph
hours_to_show: 999
entities:
- entity: sensor.pv_panels_energy
type: table
period:
"0": day
statistic: state
columnwidth:
- 16
- 20
header:
values:
- Date
- value
fill:
color: $ex css_vars["primary-color"]
font:
color: $ex css_vars["primary-text-color"]
filters:
- delta
cells:
values:
- |
$ex xs.toReversed().map(x=>
new Intl.DateTimeFormat('de-DE', {
day: '2-digit',
month: '2-digit',
year: '2-digit'
}).format(x))
- $ex ys.toReversed()
align:
- center
- left
fill:
color: $ex css_vars["card-background-color"]Beispiel 2: mehrere Spalten mit verschiedenen Sensoren:

type: custom:plotly-graph
hours_to_show: 999999
entities:
- entity: sensor.heating_water_energy
type: table
period:
"0": day
statistic: sum
filters:
- delta
- store_var: water
- entity: sensor.flowmeter_sum
type: table
period:
"0": day
statistic: sum
columnwidth:
- 16
- 10
- 10
header:
values:
- Date
- Flowmeter
- Water
fill:
color: $ex css_vars["primary-color"]
font:
color: $ex css_vars["primary-text-color"]
filters:
- delta
cells:
values:
- |
$ex xs.toReversed().map(x=>
new Intl.DateTimeFormat('de-DE', {
day: '2-digit',
month: '2-digit',
year: '2-digit'
}).format(x))
- $ex ys.toReversed().map(x=> x.toFixed(2))
- $ex vars.water.ys.map(x=> x.toFixed(2))
align:
- center
- left
fill:
color: $ex css_vars["card-background-color"]
grid_options:
columns: full
rows: 12
Die Tabellenanischt in Plotly: funktioniert, ist aber definitiv nicht dessen Kernkompetenz. Plotly überzeugt hier weder optisch noch in der Bedienung (Scrollverhalten). Die Daten können auch nicht brauchbar exportiert, oder in die Zwischenablage kopiert werden. Aus den genannten Gründen kann ich Plotly für die Anzeige von Tabelle nicht empfehlen.
Hier der Beitrag nochmal als YouTube Video:
Fazit
Home Assistant hat seine Stärken beim Anzeigen aktueller Werte und besitzt großartige Möglichkeiten zur Datenvisualisierung. Dennoch bieten bestimmte andere Lösungen hier mehr für das Speichern und Anzeigen historischer Daten. Nicht nur beim Visualisieren von Charts, auch bei der Anzeige von Tabellen könnte sich Home Assistant ein Beispiel an anderen Visualisierungslösungen, wie Grafana nehmen. Als Lösung arbeite ich parallel zu dieser Anleitung an eine HACS-Integration: Jetzt verfügbar: Tabellen & Auswertungen in Home Assistant.
 ({{pro_count}})
({{pro_count}})
{{percentage}} % positiv
 ({{con_count}})
({{con_count}})